
AI Hardware and its evolution
Introduction
Artificial Intelligence has been the cause of a contemporary revolution in almost every field, on every level. Development ranges from the narrow focus, like within healthcare, where new AI and machine learning technologies are being used to assist doctors in making wholistic diagnosis by usage of deep data analysis. Modern AI advancements have brought about powerful tools that can analyze vast amounts of data, identify patterns or trends, and even generate creative content; and as such is being used in the broader scope of the financial, manufacturing and entertainment sectors. One particularly controversial area within AI is the development of Large Language Models (LLMs). These complex algorithms are trained on massive datasets of text, allowing them to perform a wide range of Natural Language Processing (NLP) tasks. Despite the leaps in progress AI has seen over the past few years, these advancements don’t come without a cost. That cost comes in the form of high-performance computing. The intricate calculations and vast datasets involved in training and running LLMs necessitate powerful and resource intensive processing with specialized architectures. Graphics processing units (GPU) have been one of the most utilized resources for building the machines capable of delivering AI to its many applications. GPUs and their parallel processing capabilities and specialized hardware features make them ideal for LLM applications.
Evolution of Hardware in High-Performance Computing
The quest for ever-increasing computing power has driven the evolution of processor design in the realm of High-Performance Computing (HPC). Traditionally, Central Processing Units (CPUs) with architecture optimized for executing sequential instructions excelled in handling general-purpose tasks, their limitations became evident when dealing with the complex and data-intensive nature of AI workloads (Merritt, 2023). One key limitation lies in the sequential processing nature of CPUs. CPUs handle instructions one at a time, even when dealing with tasks that could be broken down into smaller, steps that could be run in parallel. This step-by-step approach creates bottlenecks when tackling massive datasets and calculations associated with AI applications, especially LLM training (Fidan, 2018). Parallel processing utilizes multiple processing units, each known as a cores, working simultaneously on different parts of a task. Imagine a team working on a large project; with parallel processing, each team member focuses on a specific aspect concurrently to one-another, reducing the overall time it takes to produce a final product. This is precisely the advantage parallel processing offers for AI workloads. By breaking down computations into smaller, independent tasks and distributing them across multiple cores, parallel processing allows for significant performance gains in AI applications (Merritt, 2023). The next major leap in processor design for HPC came with the rise of Graphics Processing Units (GPUs). Unlike CPUs designed for sequential processing, GPUs were originally built for rendering graphics in video games and other visually demanding tasks that require pixels are drawn on a screen in a certain position quickly. Their underlying architecture, specifically their focus on parallel processing, makes them remarkably well-suited for the data-parallel nature of AI computations (Fidan, 2018). GPUs also come with a significantly higher number of cores compared to CPUs. These cores, while individually less powerful than CPU cores, can work concurrently on separate parts of a task. LLMs require access to vast amounts of data during training, which and frequently make use of the high bandwidth memory GPUs come equipped with; and thus enable them to rapidly transfer data between the memory and processing cores, significantly accelerating the overall process (Merritt, 2023).
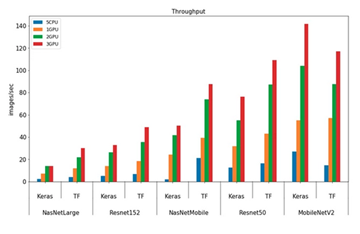
Figure 1. Performance of Deep Learning AI models, comparing CPU vs. GPU performance (Fidan, 2023)
Some GPU vendors, like NVIDIA, have incorporated specialized hardware features specifically designed to tackle AI workloads. A prime example is NVIDIA’s Tensor Cores, which are dedicated hardware units optimized for performing matrix multiplications, a fundamental operation in deep learning algorithms used by LLMs (Merritt, 2023). Looking towards the future, processor design for HPC is likely to see continued advancements in parallel processing architectures, even higher-bandwidth memory solutions, and further specialization of hardware for AI workloads. The shift from traditional CPUs to GPUs, with their focus on parallel processing and specialized hardware, has been a major turning point in this evolution. As AI continues to advance, we can expect to see even more innovative processor designs emerge to meet the ever-growing demands of high-performance computing.
The Role of GPU Memory in LLMs
Large Language Models are incredibly memory intensive due to the large amount of data required to be on hand for smooth operation. This is where the GPUs Video Memory, also known as VRAM, comes into play. VRAM acts as a temporary storage space for GPUs, and allows for close and rapid data transfer when required. It holds the data and model parameters that the GPU needs to access quickly during LLM training and usage. The amount and speed of this memory directly impacts the performance of LLMs. There are a few different types of VRAM offer varying levels of performance like GDDR6 and HBM2. GDDR6 is currently the most widely used type, and offers a good balance between capacity and speed. HBM2 (High Bandwidth Memory 2) stacks memory chips directly on top of the GPU processor, enabling significantly faster data transfer speeds compared to GDDR6 but typically much more expensive. Faster memory like HBM2 can significantly reduce the time it takes for the GPU to access data, and ensuring sufficient memory capacity means that the entire dataset and model parameters can be stored on the GPU, avoiding the need to constantly swap data with slower system memory.
Conclusion
In pursuit of a revolution in productivity both inside and out of the computing space, artificial intelligence has clearly staked itself as a technology that has many hurdles to be overcome. As with any new technology like AI, it takes time for the foundational technologies to get to the point where it is no longer restricting the development of the future technologies. At its current point, AI stands to be the largest driver for advancement and investment into high performance computing. This limitations of traditional CPUs for AI workloads and how the rise of GPUs, with their focus on parallel processing and specialized hardware, have been able to revolutionize the field so far. Massive number of cores, high-bandwidth memory, and specialized hardware like Tensor Cores make GPUs ideal for handling the complex computations required by LLMs, and will prove to be one of the foundational advancements for AI in the future. With this change, the complexity of these models continues to develop, and thus necessitates continuous advancements in processor design, with a focus on even more powerful parallel processing architectures, faster memory solutions, and further hardware specialization for AI tasks. Beyond advancements in hardware, the software ecosystem available to developers will also play a vital role in ensuring this technology is available in every field. As AI continues to evolve, the co-development of advanced processors, high-performance memory, and software will be paramount in meeting the demands of high-performance computing for the future of AI.
References
A Deeper Look At VRAM On GeForce RTX 40 Series Graphics Cards. (n.d.). NVIDIA. https://www.nvidia.com/en-us/geforce/news/rtx-40-series-vram-video-memory-explained/ MacLean, A. (n.d.). – How AI Can Help Doctors As They Solve Complex Problems. Forbes. Retrieved April 26, 2024, from https://www.forbes.com/sites/forbestechcouncil/2023/06/09/how-ai-can-help-doctors-as-they-solve-complex-problems/?sh=598d2fdb7778 – Merritt, R. (2023, December 4). Why GPUs Are Great for AI. NVIDIA Blog. https://blogs.nvidia.com/blog/why-gpus-are-great-for-ai/ – Salvaris, M. (n.d.). GPUs vs CPUs for deployment of deep learning models. Azure.microsoft.com. https://azure.microsoft.com/en-us/blog/gpus-vs-cpus-for-deployment-of-deep-learning-models/ – Stanford AI Index Report 2023 – Artificial Intelligence Index. (n.d.). Aiindex.stanford.edu. Retrieved April 26, 2024, from https://aiindex.stanford.edu/ai-index-report-2023/ – The Evolution of HPC. (2016, August 24). InsideHPC. https://insidehpc.com/2016/08/the-evolution-of-hpc/ – Types of VRAM Explained: HBM vs. GDDR5 vs. GDDR5X. (2017, February 9). https://blog.logicalincrements.com/2017/02/types-vram-explained-hbm-vs-gddr5-vs-gddr5x/ –